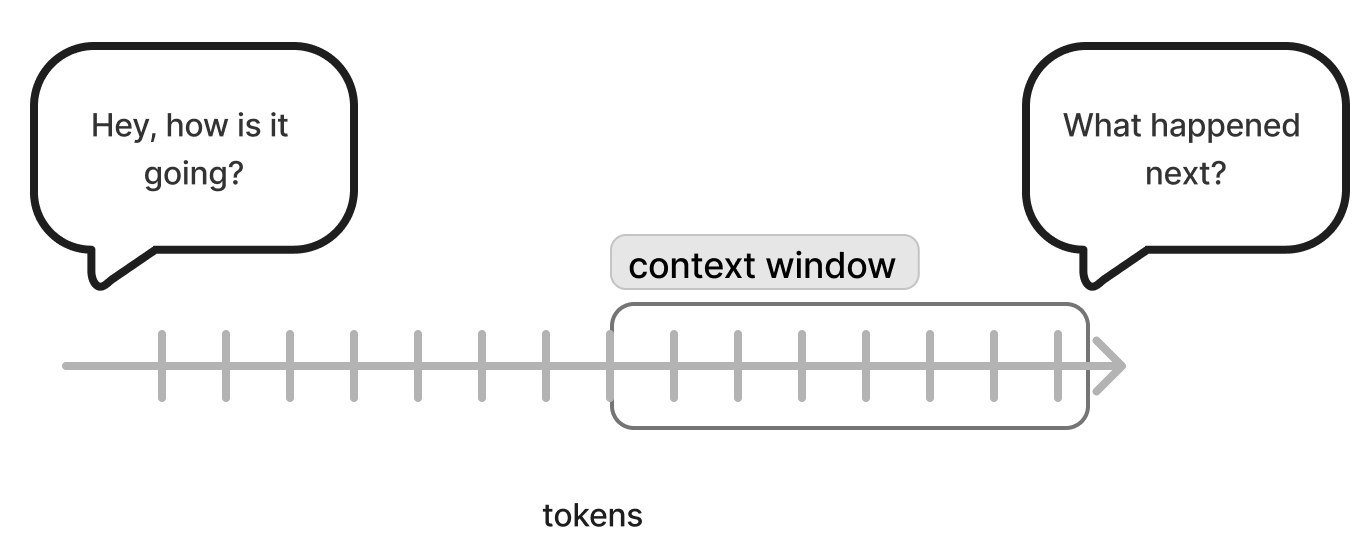
In LLMs the equivalent of human words and memory are tokens and the context window. LLMs break words and sentences into tokens, and the size of the context window determines the maximum number of tokens an LLM can process at once.
The LLM will not remember any bit that is outside of the context window. If your conversation is too long, it will forget how it started.
To illustrate how tokens work, we use OpenAI’s tiktoken library and break a sentence down into tokens.
import tiktoken# Choose the encoding based on the modelencoding = tiktoken.encoding_for_model("gpt-4o")text ="Supercalifragilisticexpialidocious is a real word."# Tokenizetokens = encoding.encode(text)print([encoding.decode([t]) for t in tokens])
When ChatGPT launched in November 2022, the model it used had a context window of 2,048 tokens. For context, I count the tokens in one of my blog posts by piping the post into strip-tags and then into ttok, a command line wrapper for the token countign library I used above1:
So, in the first version of ChatGPT, it would have forgotten about the beginnnig of my blog post as soon as it had ingested the whole post, leaving less than zero space for asking questions.
With a small context window, the only way to converse with your documents is to train the model on them or use RAG (Retrieval-Augmented Generation)2. RAG splits documents into fragments, uses embeddings for semantic search3, and retrieves relevant parts before responding.
Using RAG, your prompt would look like this:
[your search result fragment here] Please summarise this text for me.
Context windows have growm 1,000x
LLMs are advancing, and the “experimental” version of Google’s Gemini reportedly has a context window of 2 million tokens. If we now look at the complete works of Shakespeare (38 plays, 154 sonnets, two long narrative poems, and several other poems) and count its tokens
The Bard’s complete works amount to 1.47M tokens, equivalent to 512 blog posts, and with a context window of 2M tokens, we still have plenty to spare if we stuff it into our prompt and start asking questions.
Some have said this means RAG is dead, but for larger datasets there is still a place for it.
The Enron emails
One dataset that fascinates me is the Enron email dataset, which contains over 500,000 emails from more than 150 employees. While I haven’t found a verified source, it’s been reported that someone used LLM techniques to uncover an email suggesting criminal activity - hidden within sarcasm. Because of the tone, a traditional keyword search wouldn’t have worked; only sentiment analysis could reveal it.
Could we stuff the Enron emails into our Gemini prompt and start asking questions?
Download the Enron dataset
Kaggle, the data science platform, has a lot of datasets available for download, so we use its library to fetch the Enron data.
I don’t want to crash my meager MacBook, so I read and count the data in chunks.
import pandas as pddef count_tokens(text, model="gpt-4o"): encoding = tiktoken.encoding_for_model("gpt-4o")returnlen(encoding.encode(text))# Define chunk size (e.g., 10,000 rows at a time)chunk_size =10000total_tokens =0# Read the CSV in chunksfor chunk in pd.read_csv(path +"/emails.csv", usecols=["message"], chunksize=chunk_size):# Convert to string and count tokens in the batch chunk["token_count"] = chunk["message"].astype(str).map(count_tokens)# Sum up tokens in the chunk total_tokens += chunk["token_count"].sum()print(f"Total tokens in '{column_name}': {total_tokens:,}")
Total tokens in 'message': 425,303,390
Warning: This number seems high. If the average email had 100 words, I’d expect around 50M tokens, not 425M. There might be a bug in the code, or the high count could be because the metadata is included in the count along the actual email content.
To RAG or not to RAG
The Enron data is too big to stuff all of it into a prompt and start typing, even for Google’s latest 2M token context window. Does that mean RAG is the solution? Maybe. Or should we train a model using the Enron data and see if it can find the incriminating evidence that way? Possibly. That’s for a future post.
Astral’s uv turns one year old today. When I counted the tokens using the command line, I used strip-tags and ttok, but thanks to uv I didn’t need to install them, I just used uvx. Check out uv now if you haven’t already.
Footnotes
We use Simon Willison’s strip-tags to strip HTML tags, ttok to count tokens, and uvx so we don’t have to install the two packages. More on those two packages on Simon’s blog.↩︎